LLMs (as their name states) originally aim at dealing with unstructured data in text format. But can they be applied to structured information, understand, extract and transform tabular data? The answer is “Yes, but…”. Let’s deal with it together. In this article you’ll find the answers to the three main questions:
- How to transform tabular data before feeding to LLMs?
- How to create context and a prompt?
- What kind of framework should be used?
… and of course you’ll see a lot of examples!
How to transform tabular data?
I’ll address this question based on a wonderful article by Fang et al. “Large Language Models on Tabular Data: Prediction, Generation, and Understanding — A Survey” (2024) which I highly recommend for those who want to dive into the topic. The survey splits existing researches into three groups of table serialization techniques:
- text-based methods,
- embedding-based methods,
- graph-based & tree-based methods.
Text-based serialization methods includes a variety of approaches:
- DFLoader — simply use Pandas DataFrame as an input to an LLM (Singha et al. (2023)),
- JSON — transform your data table into a JSON format (Singha et al. (2023); Sui et al. (2023b)),
- Data Matrix — transformation into a data matrix (Singha et al. (2023)),
- Markdown — transform the table into Markdown, that’s one of the most popular approaches (Singha et al. (2023); Liu et al. (2023e); Zhang et al. (2023d); Ye et al. (2023b); Zhao et al. (2023d); Sui et al. (2023b)),
- X-Separated — transform the table into X-separated values where X could be a reasonable delimiter like tab or comma (Singha et al. (2023); Narayan et al. (2022)),
- Attribute-Value pairs — transform the table into pairs like name:helen ; age:47 (Wang et al. (2023c)),
- HTML — use transformation to HTML (Singha et al. (2023); Sui et al. (2023c; b)),
- Sentences — convert the table into a text like “name is helen, age is 47” (Yu et al.(2023); Hegselmann et al.(2023); Gong et al. (2020)).
Alternatively one can employ table encoders, which were fine-tuned from pre-trained LMs, to encode tabular data into numerical representations as the input for LLMs. There is a number of examples of using encoders built on:
- BERT (TAPAS (Herzig et al., 2020), TABERT (Yin et al., 2020b), TURL (Deng et al., 2022a), TUTA (Wang et al., 2021), TABBIE (Iida et al., 2021), UTP (Chen et al., 2023a)),
- or LLMs (UniTabPT (Sarkar & Lausen, 2023) (based on T5 and Flan-T5 models), TableGPT (Gong et al., 2020) (based on GPT2), TableGPT2 (Zha et al., 2023) (based on Phoenix (Chen et al., 2023b))).
Finally, the third but rarely used option is to convert a table to a tree or a graph. However, when working with sequence-to-sequence models, these structures must still be converted back to text. For Zhao et al. (2023a), after converting the table into a tree, each cell’s hierarchical structure, position information, and content was represented as a tuple and fed into GPT3.5.
So which serialization technique to choose?
As always in Data Science, there’s no easy answer and one must experiment to select what’s best suits the data, model and task. But there are a few considerations from other researchers:
- Singha et al. (2023) find that for fact-checking and table transformations DFLoader and JSON work the best,
- Sui et al. (2023a) state for Tabular QA and FV tasks for GPT it’s better to use HTML or XML,
- Sui et al. (2023b)) also found markup languages, specifically HTML, outperformed X-separated formats for GPT3.5 and GPT4. Their hypothesis is that the GPT models were trained on a significant amount of web data and thus, probably exposed the LLMs to more HTML and XML formats when interpreting tables.
I suggest to experiment with DFLoader and HTML first, though in my experience DFLoader performs great enough with powerful models. Remember also, that transformation to HTML means larger number of tokens passed to an LLM which leads to larger costs and issues with context limits.
How to create context and a prompt?
Let’s turn to the second question related to prompt engineering.
As we pass tabular data as context in a prompt, we immediately face an issue for context size. Some models have short context windows and your table may not fit in it. But even it does, LLMs are inefficient in dealing with long sequences paying attention to the beginning or end of the context window mostly. And of course, more tokens means higher costs.
There’s no straightforward solution. Some researches (Herzig et al. (2020); Liu et al. (2022c)) propose to naively truncate the table which has little sense in practice. Others seek to implement additional instruments to first select only relevant tables, rows, or columns. See examples at Sui et al. (2023c), cTBLS Sundar & Heck (2023), Dong et al. (2023).
However there are some useful tips regarding prompt engineering:
- Include additional information about tables (schemas and statistics) (Sui et al. (2023c)),
- Use in-context learning (1-shot or 2-shot learning benefits the model (Chen (2023)),
- Experiment with Chain-of-Thought, Self-Consistency techniques (e.g., Chen (2023)) and role-play (Zhao et al. (2023a)).
What kind of framework to build?
Our final question is about the modeling unit. We have a few options:
- Numeric QA is a framework consisting of just an LLM meaning that we will directly ask the model a question like “What is the average payment volume per transaction for American Express?”. Zhao et al. (2023d) claims that GPT-4 outperforms open-source models in such a framework,
Numeric QA 是一个框架,仅包含一个 LLM,这意味着我们将直接向模型提出诸如“美国运通每笔交易的平均支付额是多少?”之类的问题。 Zhao et al. (2023d) 声称 GPT-4 在这样的框架中优于开源模型。 - Operation-based QA is a framework which includes an additional step of deciding which kind of operations, tables, rows, or columns to use. An example is Chain-of-Table framework (Wang et al. (2024)) that we’ll discuss later,
基于操作的问答是一个框架,它包括一个额外的步骤,即决定使用哪种操作、表格、行或列。一个例子是表格链框架(Wang et al. (2024)),我们将在后面讨论。 - Text2SQL: SQL generation is popular in the industry, with many open-source fine-tuned models available.
In the next section we’ll compare the three approaches. Ready to get your hands dirty?
Practice!
Let’s compare the three approaches: Numeric QA, Operation-based QA and Text2SQL. I will use an e-commerce data set from Kaggle and GPT-4 for all the approaches. You can find the complete notebook with code at GitHub.
To compare the three approaches I will test them on a few types of questions:
- a question about specific row (i.e. what is the width of a specific product?),
- a question requiring aggregation over one column (i.e. what is the average width of all products?),
- a question requiring to subset rows based on condition (i.e. how many products of a specific category are there?),
- a question requiring to sort the table (i.e. what are top 3 heaviest products?),
- if an algorithm allows, I’ll experiment with table merge as well.
Please note that I won’t perform a proper testing on a large enough test sample but just check a few questions for a quick understanding of potential of the three approaches.
Let’s get our data:
and the model:
Now the setting up is complete, we can start playing with the first approach.
Numeric QA
I’ll create a 1-shot learning prompt with two arguments — for user question and a data frame passed as context:
The function for Numeric QA will ingest the question, data set, model, prompt and a binary parameter to_html as I want to experiment with two serialization techniques — DFLoader and HTML:
Let’s check the approach at 4 types of questions:
Note that as we discussed conversion to HTML increased the size of context and it didn’t fit into the GPT-4 context window.
GPT-4 answered correctly the simplest question retrieving information about a specific product id. It’s interesting that converting the data to HTML helped the model to subset the rows (see the question “How many products of category exporte_lazer are there?”). But for all other types of questions regarding manipulation with the data the LLM failed.
Another downside is lack of transparency leaving zero understanding of how the model got its answer. The size of the data matters here increasing the context size, costs and possibility of error. On the positive side, the answers are formatted nicely.
Operation-based QA
I was curious to test Chain-of-Table framework that was proposed just a few months ago (Wang et al. (2024)).
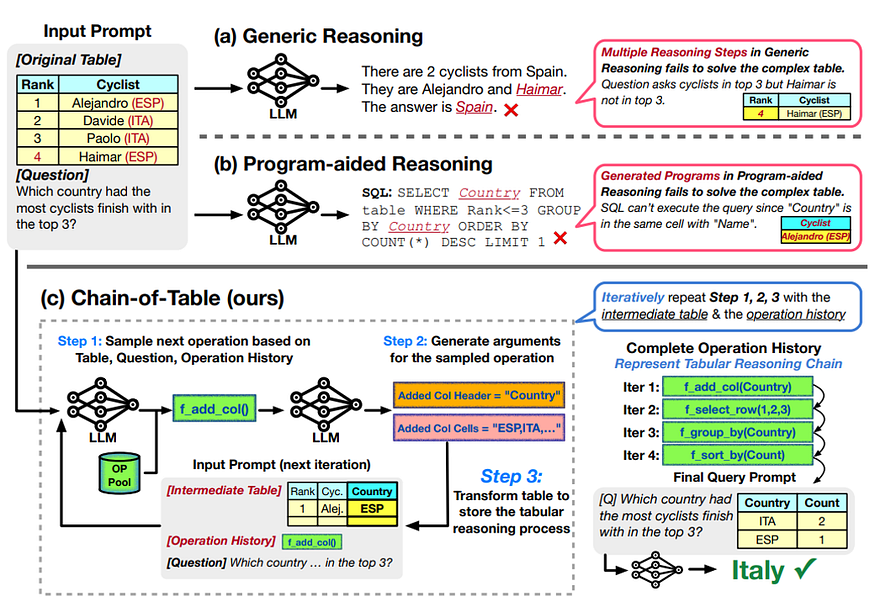
Chain-of-Table explanation from Wang et al. (2024)
The idea is very daunting. Once a user question is passed to the framework, it selects the most suitable operation from the operation pool. Possible operations are sorting, adding a column, selecting a row and grouping. Then the framework generates new arguments for the selected operation (like a name of a new column) and thansforms the data. Next, it checks whether next operations are required or the task is complete.
Let’s test the approach using ChainOfTablePack. First, get the pack and write a function, no serialization of the data is required:
Now let’s test. The pack has additional limits of data set size so once again I use a subset:
The function prints out step by step explanations which I had to truncate for the article (checkout the notebook to see the complete output) but from them it’s often seen that the model correctly performs some operations like sorting but fails when selecting the correct rows for the answer. In the end only the precise question was answered correctly. Other downsides are formatting of the answer, limited number of operations available, limitations on the sample size.
Overall I think the framework is quite promising but needs a lot improvement.
Text2SQL
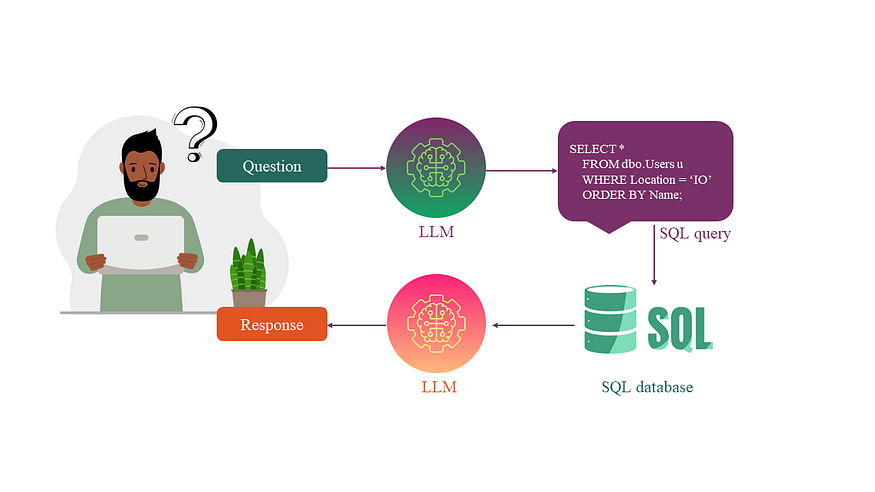
Text2SQL schema for table understanding
Finally, the star of our research is Text2SQL approach. The logic is to convert a user question into an SQL statement and execute the query (if needed, directly in the database). As I want the answer to be formatted nicely, I add another step of LLM prompting to generate an answer (or insight) based on the database reply.
Another nice feature about Text2SQL is that merging the tables is possible!
First, I create a text description of three tables. This is an optional step but very helpful for the cases when your column and table names are not informative.
Secondly, I create a 1-shot prompt to convert a user question into an SQL query:
and a 1-shot prompt to convert results of SQL querying into a nice answer:
Finally, the function for Text2SQL includes the three steps: 1) convert a question into an SQL query, 2) query the SQLite database, 3) generate a nice answer based on the data, question and query.
Let’s test Text2SQL:
Amazing! All the questions are answered correctly even the ones requiring two or three tables being merged! This approach is fully transparent as we can get information of each intermediate step, and all the answers are nicely formatted due to the second model call (check out the notebook with complete code). The context window limit is relevant only for the data description string which can be an issue only for really large databases.
There’s no serialization of data required: in the first LLM call, the model doesn’t see data at all, and in the second — the table from the database is typically quite small and DFLoader worked well there. Anyway I recommend to catch up cases when the SQL query returns too large data samples to escape high costs from LLM usage.
Conclusion
Large language models are dedicated to unstructured data and their direct application to tabular data is possible only for really simple tasks. If any kind of table manipulation (like sampling, aggregation, sorting or merging) is required, I suggest to use Text2SQL approach with one or two LLM calls depending on the task.